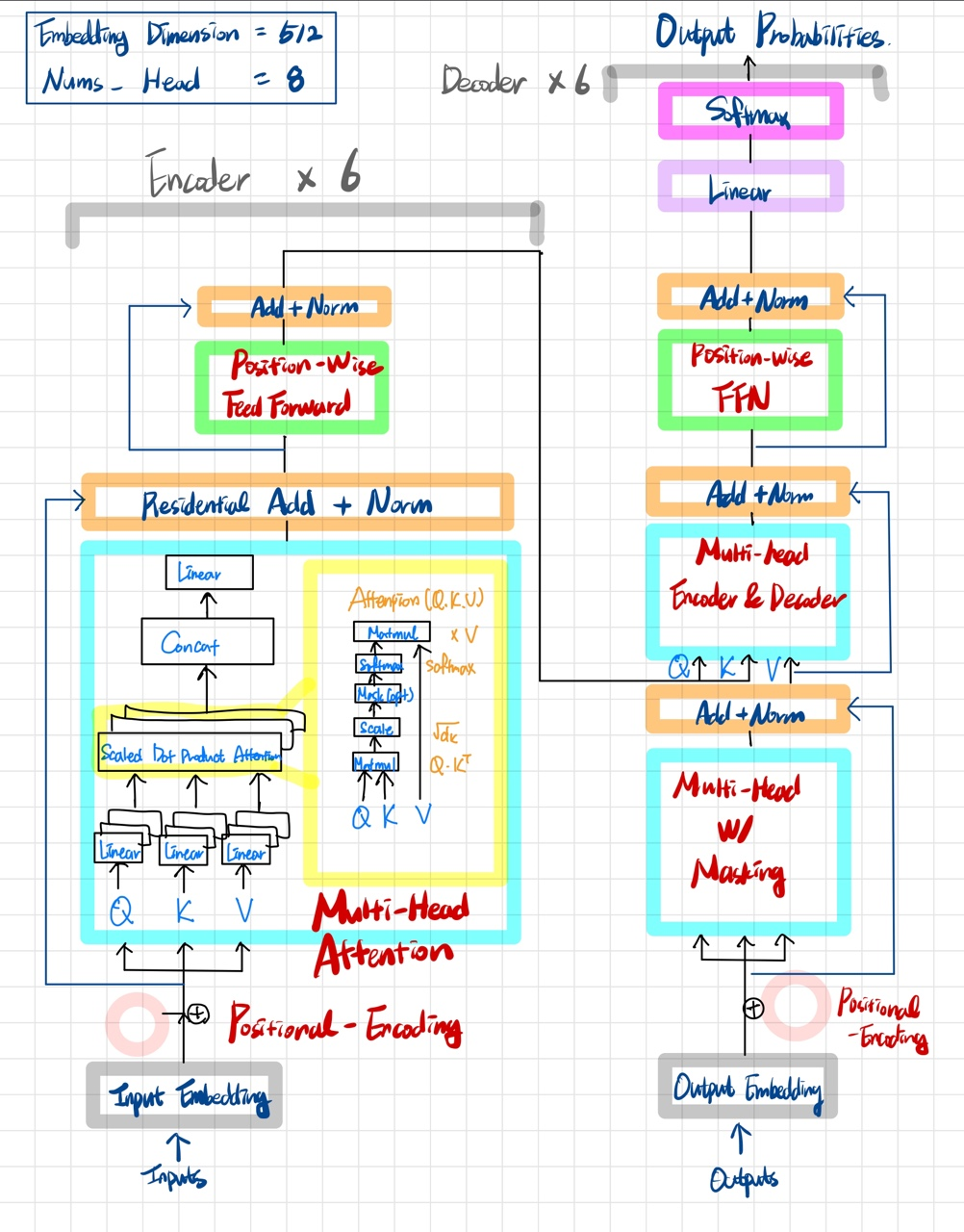
잔류 연결
2015년 ResNet에 도입된 Residual Linking이 적용되었습니다.
ResNet 살펴보기
Q9 상식에 따르면 56계층 네트워크가 20계층 네트워크보다 더 잘 수행되어야 합니다. 하지만 그렇지 않았습니다! 이유가 무엇입니까?
>>네트워크가 깊을수록 최적화(훈련)하기가 더 어렵기 때문에 네트워크가 얕을수록 성능이 더 좋습니다.
Q10. Residual Block은 매우 간단한 공식으로 표현할 수 있습니다. 수식을 적어 두십시오.
>>y = 에프(엑스) + 엑스
(7) ResNet(잔여 연결)
ResNet (2015)¶ ResNet은 ILSVRC 2015에서 우승한 모델입니다. 총 152개 레이어로 구성된 초심층 네트워크입니다. 난이도 훈련 Deep CNN¶ 2014년에 CNN의 깊이와 구조는 폭발적으로 증가했습니다.
itrepo.tistory.com
계층 정규화
정규화는 값의 분포를 고르게 만드는 과정입니다.
F7. 데이터 특성을 직접 확장하는 방법은 무엇입니까? 이러한 이유로 기능 스케일링이라고도 합니다!
>>표준화
Q8 스택 정규화와 레이어 정규화의 차이점을 적어주세요. (대리인은 최소 한 명이면 충분합니다!)
>> 스택 정규화는 스택 수준 정규화이고 수준 정규화는 기능 수준 정규화입니다.
2023년 1월 11일 – (DL) – 정규화, 정규화
정규화, 정규화
정규화 유사한 영역 또는 분포를 갖도록 입력 기능을 확장합니다. – 데이터 전처리 과정 중 하나. – 데이터의 형태를 보다 의미 있고 학습 가능하게 만드는 과정 – v with z-score 및 minmax scaler
kolazzing.com
계획된 학습률
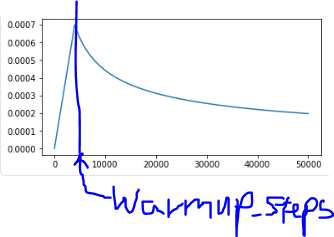

warmup_step까지 lrate는 선형적으로 증가하고,이후 step_num에 비례하여 점차 감소합니다.
이런 학습 속도에 초기 학습이 잘 되지 않는 상태에서의 학습 효율증가,
약간의 학습 후 세부 튜닝전역 최소값을 찾는 효과가 있습니다.
초기 및 후기 학습 warmup_steps 가치 기반.
체중 분포
둘 이상의 레이어가 동시에 하나의 가중치를 사용합니다.그것을 하기 위해.
가볍게 생각하면 비효율적으로 보이지만
실제로 튜닝해야 할 파라미터의 수가 줄어들수록 학습에 더 유리하고 자기 조절 효과가 있습니다.
(ResNet이 증명하듯이 많은 무게가 곧바로 성능으로 이어지지 않고,나가최적화의 불리한 추세보여주고 있음)
(변압기에서 디코더의 임베딩 레이어 및 출력 레이어의 선형 레이어의 가중치를 나누는 방법을 사용했습니다. 소스 임베딩과 타겟 임베딩도 작업에 공유되었지만 언어 유사성에 따라 선택적으로 사용됩니다. 원본 및 대상 임베딩 레이어가 공유되면 세 레이어 모두 동일한 가중치를 사용합니다.
또한 출력 레이어와 임베딩 레이어의 선형 레이어의 특징 분포가 다르기 때문에 임베딩 값은 의 제곱근을 곱하여 분포를 조정하고 위치 인코딩이 포함 값에 큰 영향을 미치지 않도록 합니다.) – from. 에펠 LMS